For visual generation, discrete autoregressive models often struggle with poor tokenizer reconstruction, difficulties in sampling from large vocabularies, and slow token-by-token generation speeds. We present BitDance, which addresses these challenges via a large-vocabulary binary tokenizer, a binary diffusion head for sampling in large discrete space, and a next-patch diffusion paradigm that enables efficient multitoken prediction. BitDance is an open-source discrete autoregressive foundation model with 14B parameters, trained on large-scale multimodal tokens. While maintaining the standard language modeling paradigm for text tokens, BitDance employs a next-patch diffusion paradigm for visual tokens to predict multiple tokens in parallel—up to 64 per step. This unified multimodal framework is simple, scalable, and capable of efficiently generating high-resolution, photorealistic images.
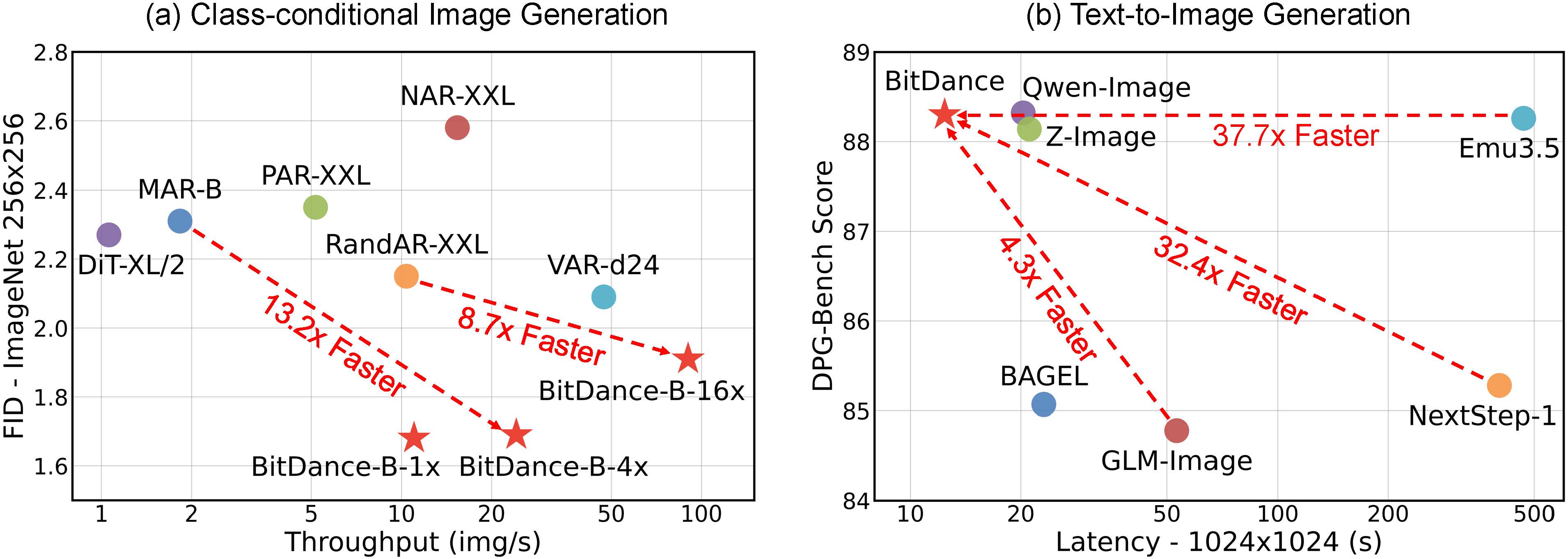
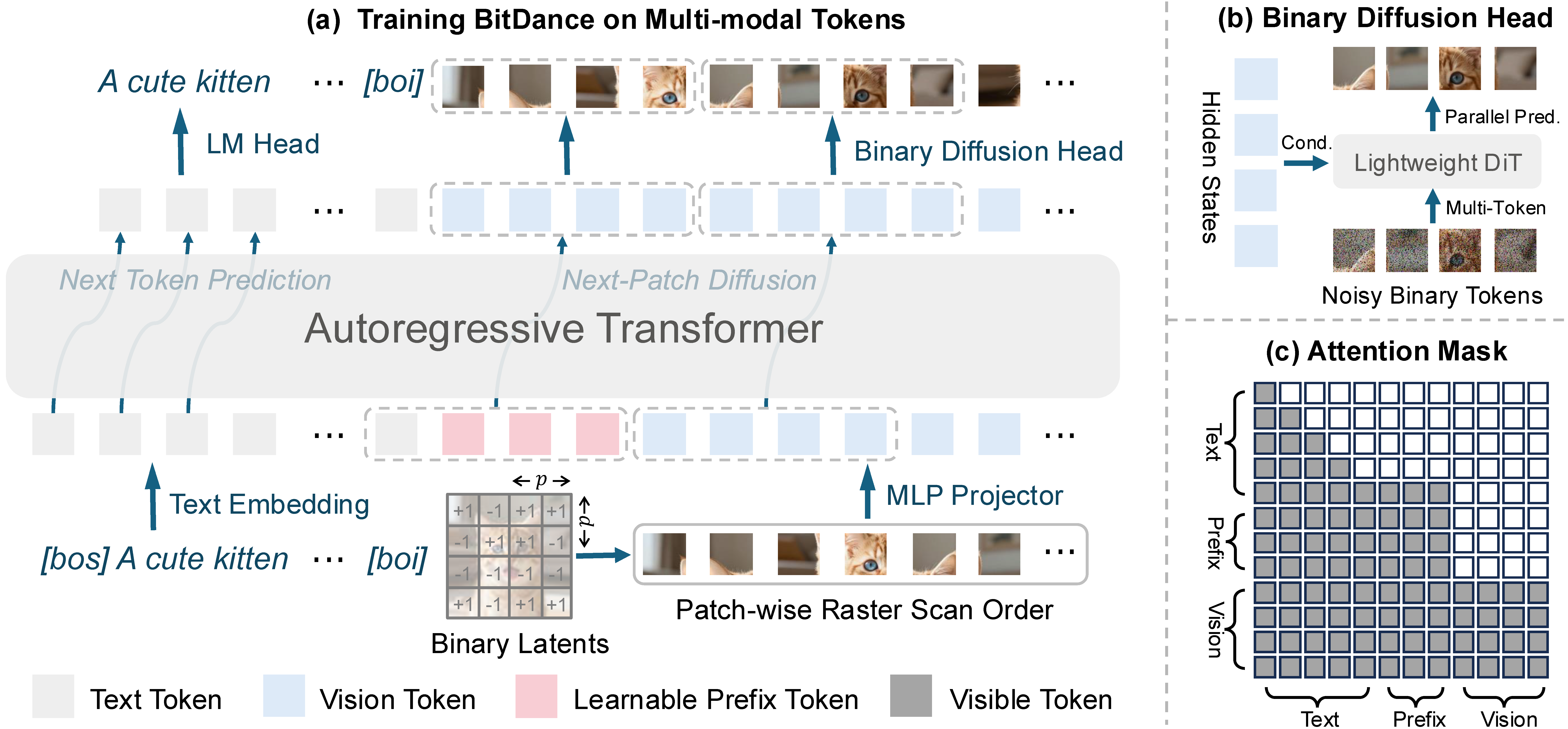
BitDance unifies a binary visual tokenizer, a diffusion-based sampling head, and a next-patch prediction strategy into a single autoregressive pipeline. Images are encoded into compact binary latents, flattened into patch-wise sequences, and decoded with joint multi-token sampling to balance quality and speed at high resolution.
The design targets three bottlenecks in autoregressive vision models: limited token expressiveness, sampling instability in large vocabularies, and slow decoding. BitDance addresses these with a 2^256 binary latent space, a diffusion head that models bit correlations directly, and patch-wise parallel prediction that preserves spatial dependencies while accelerating generation.
BitDance scales token entropy via group-wise lookup-free quantization. By partitioning channels for entropy calculation, the tokenizer can grow to a 2^256 vocabulary while staying memory efficient and preserving reconstruction fidelity comparable to continuous VAEs. Tokens are learned with entropy regularization to prevent codebook collapse, and the grouping strategy keeps training tractable even as the vocabulary grows exponentially. This yields compact sequences with strong reconstruction quality, reducing error accumulation in long autoregressive chains. The reconstruction results can be found in the below table.
| Method | Tokenizer Type | Downsample Ratio | Codebook Size | Compression Ratio | PSNR ↑ | SSIM ↑ |
|---|---|---|---|---|---|---|
| SD-VAE | Continuous | 8 | - | 24 | 23.54 | 0.68 |
| Cosmos | Discrete | 16 | 65536 | 384 | 19.93 | 0.49 |
| Show-o | Discrete | 16 | 8192 | 473 | 21.34 | 0.59 |
| LlamaGen | Discrete | 16 | 16384 | 439 | 20.65 | 0.54 |
| Open-MAGVIT2 | Discrete | 16 | 218 | 341 | 22.70 | 0.64 |
| Infinity | Discrete | 16 | 232 | 192 | 22.70 | - |
| BitDance-Tok (Ours) | Discrete | 16 | 232 | 192 | 24.90 | 0.72 |
| WeTok | Discrete | 32 | 232 | 768 | 20.77 | 0.55 |
| DC-AE | Continuous | 32 | - | 48 | 24.81 | 0.69 |
| DC-AE-SANA | Continuous | 32 | - | 48 | 24.72 | 0.69 |
| BitDance-Tok (Ours) | Discrete | 32 | 2128 | 192 | 23.26 | 0.67 |
| BitDance-Tok (Ours) | Discrete | 32 | 2256 | 96 | 25.29 | 0.74 |
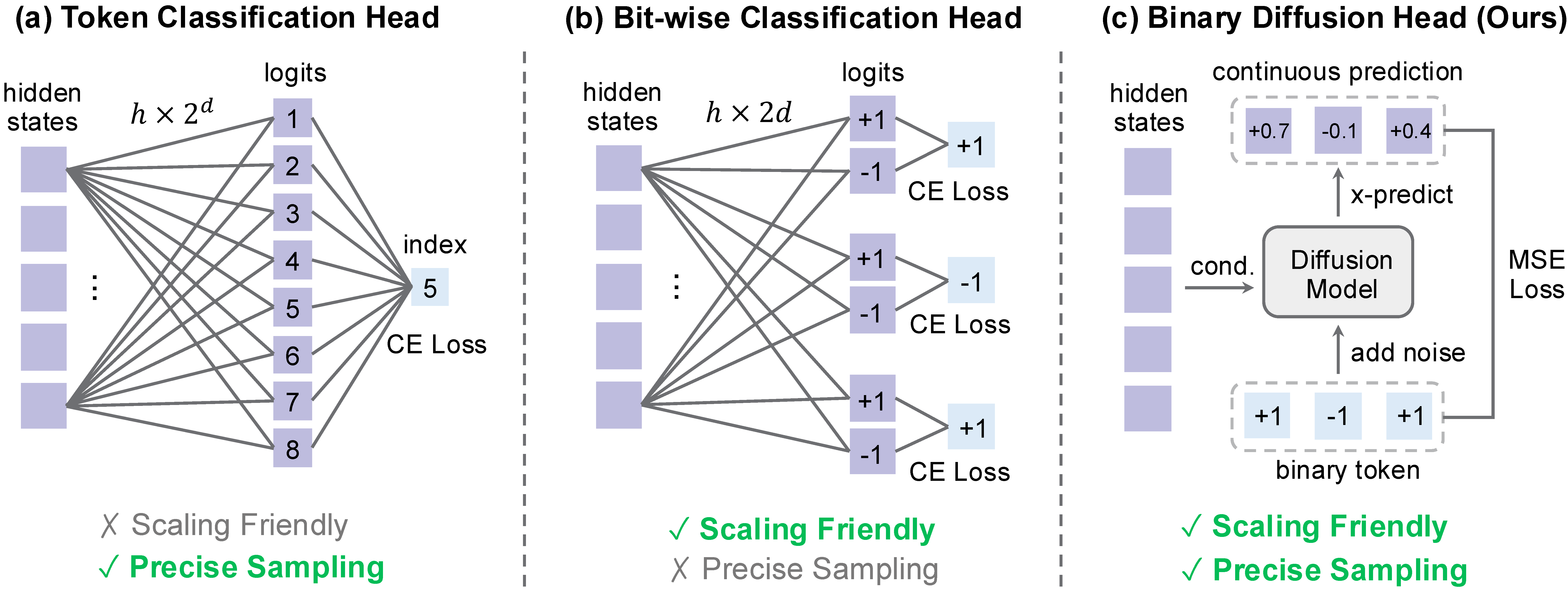
Instead of predicting a categorical index, BitDance embeds binary tokens on a continuous hypercube and trains a diffusion head with a velocity-matching objective. This models all bits jointly without exponential classifier parameters and enables high-precision sampling in massive discrete spaces.
The head predicts clean binary latents from noisy inputs and applies a hard sign projection at the end of sampling. This preserves discrete structure while avoiding the independence assumptions and parameter blowups of conventional classification heads.
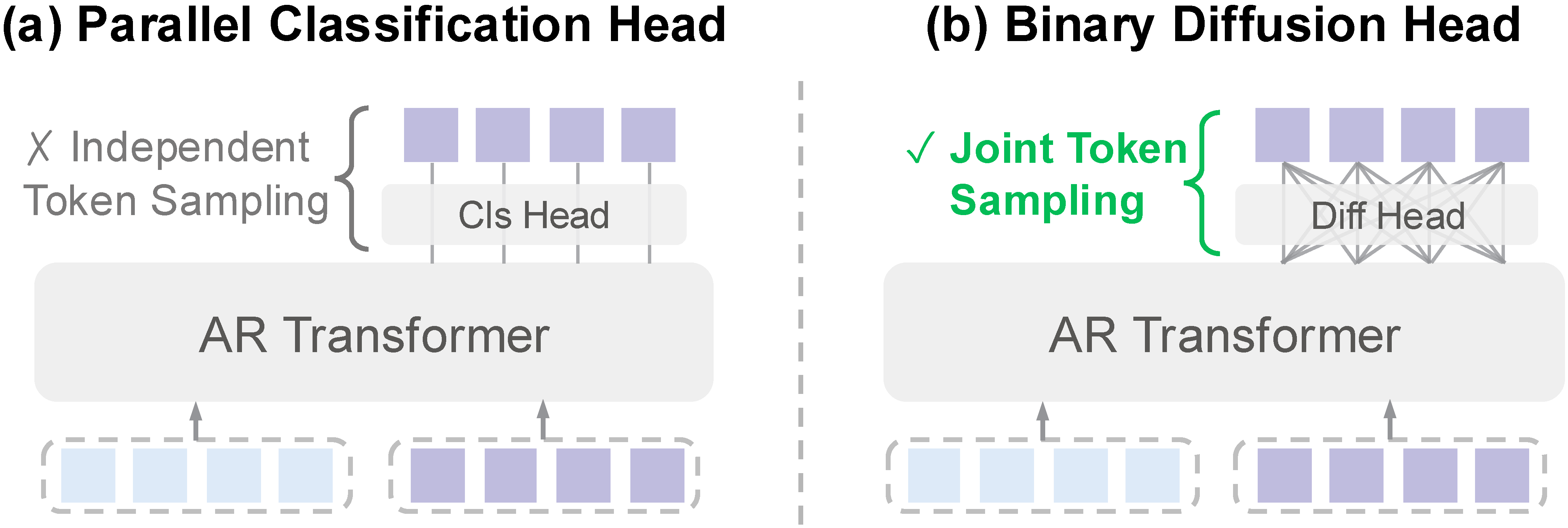
For faster decoding, BitDance predicts a patch of tokens in parallel using a block-wise causal mask that preserves dependencies within a patch. A lightweight DiT-style head aligns the training objective with joint multi-token sampling, improving both quality and throughput. Patch-wise raster ordering maintains global autoregressive structure while enabling intra-patch visibility. This closes the training-inference gap seen in parallel AR methods that sample tokens independently at inference time.
Evaluation of class-conditional image generation on ImageNet 256×256.
| Model | Type | Order | Tokenizer | #Params | FID ↓ | IS ↑ | Pre. ↑ | Rec. ↑ |
|---|---|---|---|---|---|---|---|---|
| Continuous Tokens | ||||||||
| DiT-XL/2 | Diff. | - | VAE | 675M | 2.27 | 278.2 | 0.83 | 0.57 |
| SiT-XL/2 | Diff. | - | VAE | 675M | 2.06 | 277.5 | 0.83 | 0.59 |
| DiCo-XL | Diff. | - | VAE | 701M | 2.05 | 282.2 | 0.83 | 0.59 |
| MDTv2 | Mask.+Diff. | - | VAE | 675M | 1.58 | 314.7 | 0.79 | 0.65 |
| REPA | Diff. | - | VAE | 675M | 1.42 | 305.7 | 0.80 | 0.65 |
| RAE | Diff. | - | RAE | 675M | 1.13 | 262.6 | 0.78 | 0.67 |
| MAR-B | Mask. | random | VAE | 208M | 2.31 | 281.7 | 0.82 | 0.57 |
| MAR-L | Mask. | random | VAE | 479M | 1.78 | 296.0 | 0.81 | 0.60 |
| MAR-H | Mask. | random | VAE | 943M | 1.55 | 303.7 | 0.81 | 0.62 |
| SphereAR-B | AR | raster | VAE | 208M | 1.92 | 277.8 | 0.81 | 0.61 |
| SphereAR-L | AR | raster | VAE | 479M | 1.54 | 295.9 | 0.80 | 0.63 |
| SphereAR-H | AR | raster | VAE | 943M | 1.34 | 300.0 | 0.80 | 0.64 |
| xAR-B | AR+Diff. | raster | VAE | 172M | 1.72 | 280.4 | 0.82 | 0.59 |
| xAR-L | AR+Diff. | raster | VAE | 608M | 1.28 | 292.5 | 0.82 | 0.62 |
| xAR-H | AR+Diff. | raster | VAE | 1.1B | 1.24 | 301.6 | 0.83 | 0.64 |
| Discrete Tokens | ||||||||
| LlamaGen-L | AR | raster | VQ | 343M | 3.07 | 256.1 | 0.83 | 0.52 |
| LlamaGen-XL | AR | raster | VQ | 775M | 2.62 | 244.1 | 0.80 | 0.57 |
| LlamaGen-XXL | AR | raster | VQ | 1.4B | 2.34 | 253.9 | 0.80 | 0.59 |
| RandAR-L | AR | random | VQ | 343M | 2.55 | 288.8 | 0.81 | 0.58 |
| RandAR-XL | AR | random | VQ | 775M | 2.22 | 314.2 | 0.80 | 0.60 |
| RandAR-XXL | AR | random | VQ | 1.4B | 2.15 | 322.0 | 0.79 | 0.62 |
| RAR-L | AR | hybrid | VQ | 461M | 1.70 | 299.5 | 0.81 | 0.60 |
| RAR-XL | AR | hybrid | VQ | 955M | 1.50 | 306.9 | 0.80 | 0.62 |
| RAR-XXL | AR | hybrid | VQ | 1.5B | 1.48 | 326.0 | 0.80 | 0.63 |
| OpenMAGVIT2-XL | AR | raster | LFQ | 804M | 2.51 | 271.7 | 0.84 | 0.54 |
| MAGVIT-v2 | Mask. | random | LFQ | 307M | 1.78 | 319.4 | - | - |
| VAR-d20 | VAR | - | VQ | 600M | 2.57 | 302.6 | 0.83 | 0.56 |
| VAR-d30 | VAR | - | VQ | 2B | 1.92 | 323.1 | 0.82 | 0.59 |
| BitDance-B-1x | AR | raster | LFQ | 242M | 1.68 | 297.1 | 0.80 | 0.62 |
| BitDance-L-1x | AR | raster | LFQ | 527M | 1.31 | 300.2 | 0.80 | 0.64 |
| BitDance-H-1x | AR | raster | LFQ | 1.0B | 1.24 | 304.4 | 0.81 | 0.64 |
Overall comparison with parallel image generation methods on ImageNet 256×256.
| Model | Type | Order | #Params | Steps | Throughput ↑ | FID ↓ | IS ↑ | Pre. ↑ | Rec. ↑ |
|---|---|---|---|---|---|---|---|---|---|
| DiT-XL/2 | Diff. | - | 675M | 250 | 1.06 img/s | 2.27 | 278.2 | 0.83 | 0.57 |
| DiCo-XL | Diff. | - | 701M | 250 | 2.62 img/s | 2.05 | 282.2 | 0.83 | 0.59 |
| MaskGIT | Mask. | random | 227M | 8 | 50.73 img/s | 6.18 | 182.1 | 0.80 | 0.51 |
| MAR-B | Mask. | random | 208M | 256 | 1.83 img/s | 2.31 | 281.7 | 0.82 | 0.57 |
| MAR-L | Mask. | random | 479M | 256 | 1.39 img/s | 1.78 | 296.0 | 0.81 | 0.60 |
| VAR-d20 | VAR | - | 600M | 10 | 71.31 img/s | 2.57 | 302.6 | 0.83 | 0.56 |
| VAR-d24 | VAR | - | 1.0B | 10 | 47.22 img/s | 2.09 | 312.9 | 0.82 | 0.59 |
| PAR-L | AR | hybrid | 343M | 147 | 15.01 img/s | 3.76 | 218.9 | 0.81 | 0.60 |
| PAR-XL | AR | hybrid | 775M | 147 | 8.09 img/s | 2.61 | 259.2 | 0.80 | 0.62 |
| PAR-XXL | AR | hybrid | 1.4B | 147 | 5.17 img/s | 2.35 | 263.2 | 0.80 | 0.62 |
| NAR-L | AR | hybrid | 372M | 31 | 40.03 img/s | 3.06 | 263.9 | 0.81 | 0.53 |
| NAR-XL | AR | hybrid | 816M | 31 | 23.12 img/s | 2.70 | 277.5 | 0.81 | 0.58 |
| NAR-XXL | AR | hybrid | 1.5B | 31 | 15.37 img/s | 2.58 | 293.5 | 0.82 | 0.57 |
| RandAR-L | AR | random | 343M | 88 | 25.12 img/s | 2.55 | 288.8 | 0.81 | 0.58 |
| RandAR-XL | AR | random | 775M | 88 | 16.01 img/s | 2.25 | 317.8 | 0.80 | 0.60 |
| RandAR-XXL | AR | random | 1.4B | 88 | 10.39 img/s | 2.15 | 322.0 | 0.79 | 0.62 |
| BitDance-B-4x | AR | raster | 260M | 64 | 24.18 img/s | 1.69 | 291.2 | 0.79 | 0.63 |
| BitDance-B-16x | AR | raster | 260M | 16 | 90.26 img/s | 1.91 | 283.8 | 0.78 | 0.62 |
Evaluation of text-to-image generation on DPG-Bench.
| Model | Global | Entity | Attribute | Relation | Other | Overall ↑ |
|---|---|---|---|---|---|---|
| Proprietary Models | ||||||
| GPT Image 1 | 88.89 | 88.94 | 89.84 | 92.63 | 90.96 | 85.15 |
| Seedream 3.0 | 94.31 | 92.65 | 91.36 | 92.78 | 88.24 | 88.27 |
| Diffusion Models | ||||||
| PixArt-α | 86.89 | 82.89 | 88.94 | 86.59 | 87.68 | 80.54 |
| FLUX.1-Dev | 74.35 | 90.00 | 88.96 | 90.87 | 88.33 | 83.84 |
| SD3 Medium | 87.90 | 91.01 | 88.83 | 80.70 | 88.68 | 84.08 |
| Z-Image-Turbo | 91.29 | 89.59 | 90.14 | 92.16 | 88.68 | 84.86 |
| BAGEL | - | - | - | - | - | 85.07 |
| HiDream-I1-Full | 76.44 | 90.22 | 89.48 | 93.74 | 91.83 | 85.89 |
| Lumina-Image-2.0 | - | 91.97 | 90.20 | 94.85 | - | 87.20 |
| Z-Image | 93.39 | 91.22 | 93.16 | 92.22 | 91.52 | 88.14 |
| Qwen-Image | 91.32 | 91.56 | 92.02 | 94.31 | 92.73 | 88.32 |
| Autoregressive Models | ||||||
| Emu3-Gen | 85.21 | 86.68 | 86.84 | 90.22 | 83.15 | 80.60 |
| Infinity | 93.11 | - | - | 90.76 | - | 83.46 |
| Janus-Pro | 86.90 | 88.90 | 89.40 | 89.32 | 89.48 | 84.19 |
| Tar | 83.98 | 88.62 | 88.05 | 93.98 | 84.86 | 84.19 |
| NextStep-1 | - | - | - | - | - | 85.28 |
| GLM-Image | 87.74 | 90.25 | 89.08 | 92.15 | 90.17 | 84.78 |
| BitDance | 89.53 | 93.76 | 92.47 | 91.81 | 90.26 | 88.28 |
Evaluation of text-to-image generation on GenEval.
| Model | Single Obj. | Two Obj. | Count | Colors | Pos. | Color Attri. | Overall ↑ |
|---|---|---|---|---|---|---|---|
| Proprietary Models | |||||||
| GPT Image 1 | 0.99 | 0.92 | 0.85 | 0.92 | 0.75 | 0.61 | 0.84 |
| Seedream 3.0 | 0.99 | 0.96 | 0.91 | 0.93 | 0.47 | 0.80 | 0.84 |
| Diffusion Models | |||||||
| PixArt-α | 0.98 | 0.50 | 0.44 | 0.80 | 0.08 | 0.07 | 0.48 |
| SD3 Medium | 0.98 | 0.74 | 0.63 | 0.67 | 0.34 | 0.36 | 0.62 |
| JanusFlow | 0.97 | 0.59 | 0.45 | 0.83 | 0.53 | 0.42 | 0.63 |
| FLUX.1-Dev | 0.98 | 0.81 | 0.74 | 0.79 | 0.22 | 0.45 | 0.66 |
| SD3.5-Large | 0.98 | 0.89 | 0.73 | 0.83 | 0.34 | 0.47 | 0.71 |
| Lumina-Image-2.0 | - | 0.87 | 0.67 | - | - | 0.62 | 0.73 |
| Show-o2 | 1.00 | 0.87 | 0.58 | 0.92 | 0.52 | 0.62 | 0.76 |
| Z-Image-Turbo | 1.00 | 0.95 | 0.77 | 0.89 | 0.65 | 0.68 | 0.82 |
| HiDream-I1-Full | 1.00 | 0.98 | 0.79 | 0.91 | 0.60 | 0.72 | 0.83 |
| Z-Image | 1.00 | 0.94 | 0.78 | 0.93 | 0.62 | 0.77 | 0.84 |
| Qwen-Image | 0.99 | 0.92 | 0.89 | 0.88 | 0.76 | 0.77 | 0.87 |
| BAGEL | 0.98 | 0.95 | 0.84 | 0.95 | 0.78 | 0.77 | 0.88 |
| Autoregressive Models | |||||||
| Emu3-Gen | 0.98 | 0.71 | 0.34 | 0.81 | 0.17 | 0.21 | 0.54 |
| Infinity | - | 0.85 | - | - | 0.49 | 0.57 | 0.73 |
| Janus-Pro | 0.99 | 0.89 | 0.59 | 0.90 | 0.79 | 0.66 | 0.80 |
| Tar | 0.98 | 0.92 | 0.83 | 0.85 | 0.80 | 0.65 | 0.84 |
| NextStep-1 | - | - | - | - | - | - | 0.73 |
| BitDance | 1.00 | 0.96 | 0.71 | 0.95 | 0.72 | 0.83 | 0.86 |
Evaluation of text-to-image generation on OneIG-EN.
| Model | Alignment | Text | Reasoning | Style | Diversity | Overall ↑ |
|---|---|---|---|---|---|---|
| Proprietary Models | ||||||
| Imagen 4 | 0.857 | 0.805 | 0.338 | 0.377 | 0.199 | 0.515 |
| Seedream 3.0 | 0.818 | 0.865 | 0.275 | 0.413 | 0.277 | 0.530 |
| GPT Image 1 | 0.851 | 0.857 | 0.345 | 0.462 | 0.151 | 0.533 |
| Diffusion Models | ||||||
| Show-o2 | 0.817 | 0.002 | 0.226 | 0.317 | 0.177 | 0.308 |
| SANA-1.5 | 0.765 | 0.069 | 0.217 | 0.401 | 0.216 | 0.334 |
| BAGEL | 0.769 | 0.244 | 0.173 | 0.367 | 0.251 | 0.361 |
| FLUX.1-Dev | 0.786 | 0.523 | 0.253 | 0.368 | 0.238 | 0.434 |
| OmniGen2 | 0.804 | 0.680 | 0.271 | 0.377 | 0.242 | 0.475 |
| HiDream-I1-Full | 0.829 | 0.707 | 0.317 | 0.347 | 0.186 | 0.477 |
| Z-Image-Turbo | 0.840 | 0.994 | 0.298 | 0.368 | 0.139 | 0.528 |
| Qwen-Image | 0.882 | 0.891 | 0.306 | 0.418 | 0.197 | 0.539 |
| Z-Image | 0.881 | 0.987 | 0.280 | 0.387 | 0.194 | 0.546 |
| Autoregressive Models | ||||||
| Janus-Pro | 0.553 | 0.001 | 0.139 | 0.276 | 0.365 | 0.267 |
| NextStep-1 | 0.826 | 0.507 | 0.224 | 0.332 | 0.199 | 0.418 |
| GLM-Image | 0.805 | 0.969 | 0.298 | 0.353 | 0.213 | 0.528 |
| BitDance | 0.853 | 0.937 | 0.297 | 0.395 | 0.177 | 0.532 |
Evaluation of text-to-image generation on OneIG-ZH.
| Model | Alignment | Text | Reasoning | Style | Diversity | Overall ↑ |
|---|---|---|---|---|---|---|
| Proprietary Models | ||||||
| Kolors 2.0 | 0.738 | 0.502 | 0.226 | 0.331 | 0.333 | 0.426 |
| GPT Image 1 | 0.812 | 0.650 | 0.300 | 0.449 | 0.159 | 0.474 |
| Seedream 3.0 | 0.793 | 0.928 | 0.281 | 0.397 | 0.243 | 0.528 |
| Diffusion Models | ||||||
| HiDream-I1-Full | 0.620 | 0.205 | 0.256 | 0.304 | 0.300 | 0.337 |
| CogView4 | 0.700 | 0.193 | 0.236 | 0.348 | 0.214 | 0.338 |
| BAGEL | 0.672 | 0.365 | 0.186 | 0.357 | 0.268 | 0.370 |
| Z-Image-Turbo | 0.782 | 0.982 | 0.276 | 0.361 | 0.134 | 0.507 |
| Qwen-Image | 0.825 | 0.963 | 0.267 | 0.405 | 0.279 | 0.548 |
| Z-Image | 0.793 | 0.988 | 0.266 | 0.386 | 0.243 | 0.535 |
| Autoregressive Models | ||||||
| Janus-Pro | 0.324 | 0.148 | 0.104 | 0.264 | 0.358 | 0.240 |
| GLM-Image | 0.738 | 0.976 | 0.284 | 0.335 | 0.221 | 0.511 |
| BitDance | 0.786 | 0.961 | 0.276 | 0.376 | 0.159 | 0.512 |
Evaluation of text-to-image generation on TIIF Bench testmini.
| Model | Overall (Short) | Overall (Long) | Basic Avg (Short) | Basic Avg (Long) | Attr. (Short) | Attr. (Long) | Relation (Short) | Relation (Long) | Reasoning (Short) | Reasoning (Long) | Advanced Avg (Short) | Advanced Avg (Long) | Attr+Rela (Short) | Attr+Rela (Long) | Attr+Reas (Short) | Attr+Reas (Long) | Rela+Reas (Short) | Rela+Reas (Long) | Style (Short) | Style (Long) | Text (Short) | Text (Long) | Real World (Short) | Real World (Long) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Proprietary Models | ||||||||||||||||||||||||
| Midjourney V7 | 68.74 | 65.69 | 77.41 | 76.00 | 77.58 | 81.83 | 82.07 | 76.82 | 72.57 | 69.32 | 64.66 | 60.53 | 67.20 | 62.70 | 81.22 | 71.59 | 60.72 | 64.59 | 83.33 | 80.00 | 24.83 | 20.83 | 68.83 | 63.61 |
| DALL-E 3 | 74.96 | 70.81 | 78.72 | 78.50 | 79.50 | 79.83 | 80.82 | 78.82 | 75.82 | 76.82 | 73.39 | 67.27 | 73.45 | 67.20 | 72.01 | 71.34 | 63.59 | 60.72 | 89.66 | 86.67 | 66.83 | 54.83 | 72.93 | 60.99 |
| Seedream 3.0 | 86.02 | 84.31 | 87.07 | 84.93 | 90.50 | 90.00 | 89.85 | 85.94 | 80.86 | 78.86 | 79.16 | 80.60 | 79.76 | 81.82 | 77.23 | 78.85 | 75.64 | 78.64 | 100.00 | 93.33 | 97.17 | 87.78 | 83.21 | 83.58 |
| GPT Image 1 | 89.15 | 88.29 | 90.75 | 89.66 | 91.33 | 87.08 | 84.57 | 84.57 | 96.32 | 97.32 | 88.55 | 88.35 | 87.07 | 89.44 | 87.22 | 83.96 | 85.59 | 83.21 | 90.00 | 93.33 | 89.83 | 86.83 | 89.73 | 93.46 |
| Diffusion Models | ||||||||||||||||||||||||
| Lumina-Next | 50.93 | 52.46 | 64.58 | 66.08 | 56.83 | 59.33 | 67.57 | 71.82 | 69.32 | 67.07 | 44.75 | 45.63 | 51.44 | 43.20 | 51.09 | 59.72 | 44.72 | 54.46 | 70.00 | 66.67 | 0.00 | 0.83 | 47.56 | 49.05 |
| Hunyuan-DiT | 51.38 | 53.28 | 69.33 | 69.00 | 65.83 | 69.83 | 78.07 | 73.82 | 64.07 | 63.32 | 42.62 | 45.45 | 50.20 | 41.57 | 59.22 | 61.84 | 47.84 | 51.09 | 56.67 | 73.33 | 0.00 | 0.83 | 40.10 | 44.20 |
| PixArt-Σ | 62.00 | 58.12 | 70.66 | 75.25 | 69.33 | 78.83 | 75.07 | 77.32 | 67.57 | 69.57 | 57.65 | 49.50 | 65.20 | 56.57 | 66.96 | 61.72 | 66.59 | 54.59 | 83.33 | 70.00 | 1.83 | 1.83 | 62.11 | 52.41 |
| SANA 1.5 | 67.15 | 65.73 | 79.66 | 77.08 | 79.83 | 77.83 | 85.57 | 83.57 | 73.57 | 69.82 | 61.50 | 60.67 | 65.32 | 56.57 | 69.96 | 73.09 | 62.96 | 65.84 | 80.00 | 80.00 | 17.83 | 15.83 | 71.07 | 68.83 |
| SD 3 | 67.46 | 66.09 | 78.32 | 77.75 | 83.33 | 79.83 | 82.07 | 78.82 | 71.07 | 74.07 | 61.46 | 59.56 | 61.07 | 64.07 | 68.84 | 70.34 | 50.96 | 57.84 | 66.67 | 76.67 | 59.83 | 20.83 | 63.23 | 67.34 |
| FLUX.1-dev | 71.09 | 71.78 | 83.12 | 78.65 | 87.05 | 83.17 | 87.25 | 80.39 | 75.01 | 72.39 | 65.79 | 68.54 | 67.07 | 73.69 | 73.84 | 73.34 | 69.09 | 71.59 | 66.67 | 66.67 | 43.83 | 52.83 | 70.72 | 71.47 |
| Z-Image-Turbo | 77.73 | 80.05 | 81.85 | 81.59 | 86.50 | 87.00 | 82.88 | 79.99 | 76.17 | 77.77 | 68.32 | 74.69 | 72.04 | 75.24 | 60.22 | 73.33 | 68.90 | 71.92 | 83.33 | 93.33 | 83.71 | 84.62 | 85.82 | 77.24 |
| Z-Image | 80.20 | 83.04 | 78.36 | 82.79 | 79.50 | 86.50 | 80.45 | 79.94 | 75.13 | 81.94 | 72.89 | 77.02 | 72.91 | 77.56 | 66.99 | 73.82 | 73.89 | 75.62 | 90.00 | 93.33 | 94.84 | 93.21 | 88.06 | 85.45 |
| Qwen-Image | 86.14 | 86.83 | 90.18 | 87.22 | 90.50 | 91.50 | 88.22 | 90.78 | 79.81 | 79.38 | 79.30 | 80.88 | 79.21 | 78.94 | 78.85 | 81.69 | 75.57 | 78.59 | 100.00 | 100.00 | 92.76 | 89.14 | 90.30 | 91.42 |
| Autoregressive Models | ||||||||||||||||||||||||
| LightGen | 53.22 | 43.41 | 66.58 | 47.91 | 55.83 | 47.33 | 74.82 | 45.82 | 69.07 | 50.57 | 46.74 | 41.53 | 62.44 | 40.82 | 61.71 | 50.47 | 50.34 | 45.34 | 53.33 | 53.33 | 0.00 | 6.83 | 50.92 | 50.55 |
| Infinity | 62.07 | 62.32 | 73.08 | 75.41 | 74.33 | 76.83 | 72.82 | 77.57 | 72.07 | 71.82 | 56.64 | 54.98 | 60.44 | 55.57 | 74.22 | 64.71 | 60.22 | 59.71 | 80.00 | 73.33 | 10.83 | 23.83 | 54.28 | 56.89 |
| Janus-Pro | 66.50 | 65.02 | 79.33 | 78.25 | 79.33 | 82.33 | 78.32 | 73.32 | 80.32 | 79.07 | 59.71 | 58.82 | 66.07 | 56.20 | 70.46 | 70.84 | 67.22 | 59.97 | 60.00 | 70.00 | 28.83 | 33.83 | 65.84 | 60.25 |
| GLM-Image | 81.01 | 81.02 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| BitDance | 79.64 | 78.12 | 78.79 | 80.44 | 83.50 | 87.50 | 77.22 | 77.62 | 75.64 | 76.21 | 72.19 | 71.66 | 72.89 | 78.88 | 68.06 | 66.10 | 70.63 | 67.21 | 96.67 | 90.00 | 87.78 | 75.57 | 84.33 | 83.96 |
@article{ai2026bitdance,
title = {BitDance: Scaling Autoregressive Generative Models with Binary Tokens},
author = {Ai, Yuang and Han, Jiaming and Zhuang, Shaobin and Hu, Xuefeng and Yang, Ziyan and Yang, Zhenheng and Huang, Huaibo and Yue, Xiangyu and Chen, Hao},
journal = {arXiv preprint arXiv:2602.14041},
year = {2026}
} Paper
Paper
 Code
Code Models
Models